Recipe Distiller site domain popularity and the 80-20 rule
July 3, 2011
Software
I’ve previously claimed that the main compelling feature of Recipe Distiller is its ability to automatically extract ingredients from any recipe site. However, it is quite possible that I am blinded by the fact that this is the most technically interesting part of the application. It does not necessarily follow that it is a useful feature for people.
So, I thought I would take the blinders off and put together a little chart showing the number of recipes that have been saved by domain to see if this is actually the case:
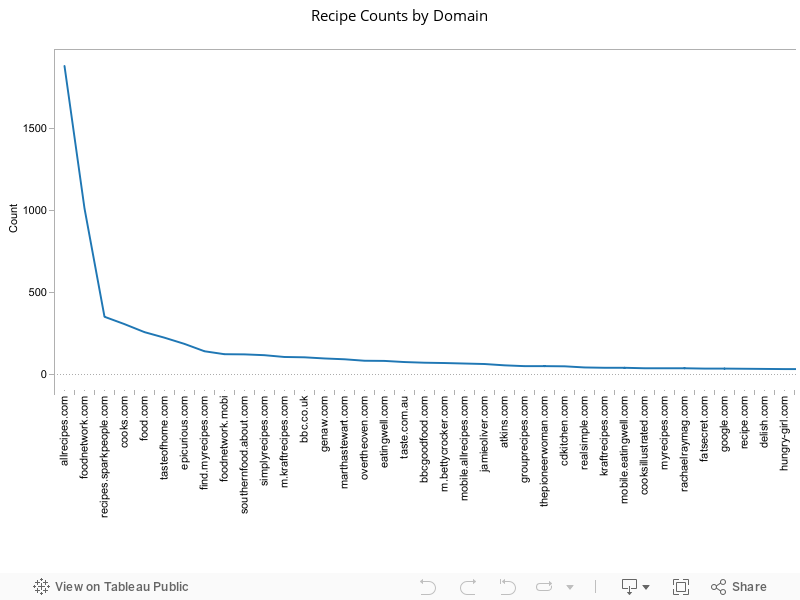
There are 1010 different site domains represented in the chart. As you can see, the top 10 sites dominate the overall saved recipe counts. They represent about 50% of the total number of saved recipes.
| Domain | Recipe Count |
|---|---|
| allrecipes.com | 1885 |
| foodnetwork.com | 1014 |
| recipes.sparkpeople.com | 351 |
| cooks.com | 306 |
| food.com | 257 |
| tasteofhome.com | 223 |
| epicurious.com | 185 |
| find.myrecipes.com | 140 |
| foodnetwork.mobi | 122 |
| southernfood.about.com | 121 |
(The data is a tad dirty in that foodnetwork.com and footnetwork.mobi are counted as two separate domains. A more thorough analysis would try and conflate these types of duplicates)
The 80-20 rule appears to apply here as well. If you scroll the chart out to the right, you will see an annotation indicating the domain that marks the end of the top 20% of the recipe site domains. The domains in the top 20% account for 86% of all saved recipes on the site.
That’s a pretty high percentage so it would make sense to focus exclusively on these. A custom screen scraper is a lot more accurate than the automated ingredient extraction algorithm that Recipe Distiller uses so why not just build out a bigger library of scrapers that work with the top 20%? The problem is that the top 20% represents just over 200 different screen scrapers that need to be built and then maintained if sites change their markup. If you look at the competing products out there, they generally only support somewhere between 10-30 different recipe sites. Building out a scraper library that is large enough to capture a sizable portion of the long tail is subject to seriously diminishing returns on developer time once you get passed that top 30 point. Furthermore, the counts drop off a cliff very quickly and I suspect there will be a lot of churn at the bottom end of that 20%. You will always be in a reactive mode if you try to use scrapers exclusively.
A hybrid approach might be better: Build out special scrapers for the top 10-30 but then fallback to the automated (but less accurate) algorithm for the rest.
A couple of caveats to all of this:
- Small sample size, yadda yadda yadda
- The data is being drawn from a potentially biased set of users. Recipe Distiller is marketed as being usable with any recipe site so it is certainly possible that the people using it are the types to specifically seek out the non-mainstream sites for recipes.