Cryptopals Challenge 19
January 3, 2017
Software
I’ve been (very) slowly working my way through the cryptopals cryptochallenges and I’ve found that going through the exercise of actually building out well-known attacks is a great way of demonstrating exactly why it is important to practice proper crypto-hygiene and, more importantly, why you should always use existing high-level libraries because it is so, so easy to get things wrong.
Challenge 19 illustrates the danger of using a fixed nonce with AES-CTR mode
encryption. In CTR mode, a keystream (K) is generated by combining a nonce
with a counter and passing that through a block cipher. Then, the keystream is
xor’ed against the plaintext (P) to produce the ciphertext (C):
K ⊕ P = C
(Wikipedia has some great diagrams illustrating the flow of the different block cipher modes.)
In this challenge, the attacker (that’s you!) is provided with a series of short sentences that have all been encrypted with a fixed nonce. This means that the same keystream has been used to encrypt every sentence. This is bad because XOR has a few magical properties:
A ⊕ A = 0
B ⊕ 0 = B
So that means, if you XOR the ciphertext with a guessed plaintext value, you can recover the keystream:
K ⊕ P ⊕ P = C ⊕ P
K ⊕ 0
K = C ⊕ P
Since the keystream is the same for all of the sentences, guessing a plaintext value for a single character in any of the sentences, will let you recover the plaintext in all of the sentences for the character in that same index position. Given that, it is now possible to construct an automated attack that uses language frequencies to run through different plaintext guesses and recover the original messages. In fact, that is exactly what Challenge 20 asks you to do.
Challenge 19, however, asks you to:
Attack this cryptosystem piecemeal: guess letters, use expected English language frequence to validate guesses, catch common English trigrams, and so on.
Which frankly is not quite as sexy as the fully-automated approach that you end up building in Challenge 20. I think this is the reason that some people skipped over this one when I googled around to see what others have tried for this challenge.
My thought was that having some sort of simple UI to experiment with different plaintext guesses would be the ideal approach here. A UI would allow me to plug in different guesses for a character in a single sentence and then quickly eyeball the revealed plaintext values in the rest of the sentences.
However, I certainly did not want to go through the work of building a web UI for this, nor did I want to put together an old-school desktop application. A console-based UI is really all that is needed for this.
Thankfully, the python curses library makes it really easy to put together a simple text UI. This was the first time I tried using it and I was pleasantly surprised with how easy it was to hack something together. The event loop is a lot simpler that a traditional Windows UI in that we don’t have to deal with arbitrary message types on the message queue. It is a lot more tightly controlled and less event-driven here: basically we: read input, “render” the text in response to the input, update the position of the cursor, and then rinse, wash, and repeat.
A simple strategy to use when actually trying to decrypt the messages is to first guess a space value in one of the sentences and check the revealed values in the other sentences. If they produce an unusual non-alphabetic symbol like a ( or ), then that is a good indication that the original guess was wrong. From there it is just a matter of examining the decrypted content in all of the sentences and letting your brain’s natural English pattern recognition take over.
Here is a recording of the TUI in action:
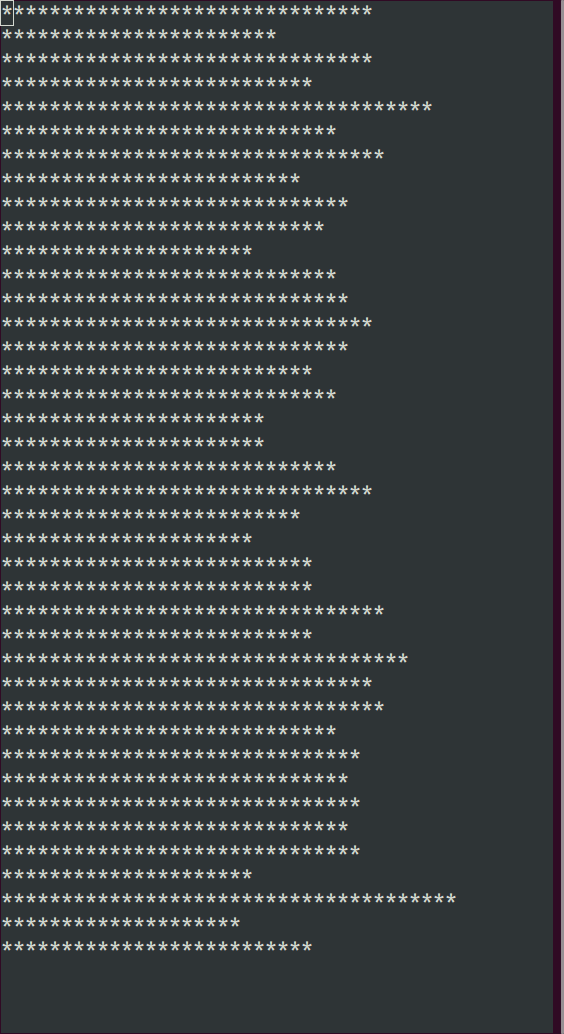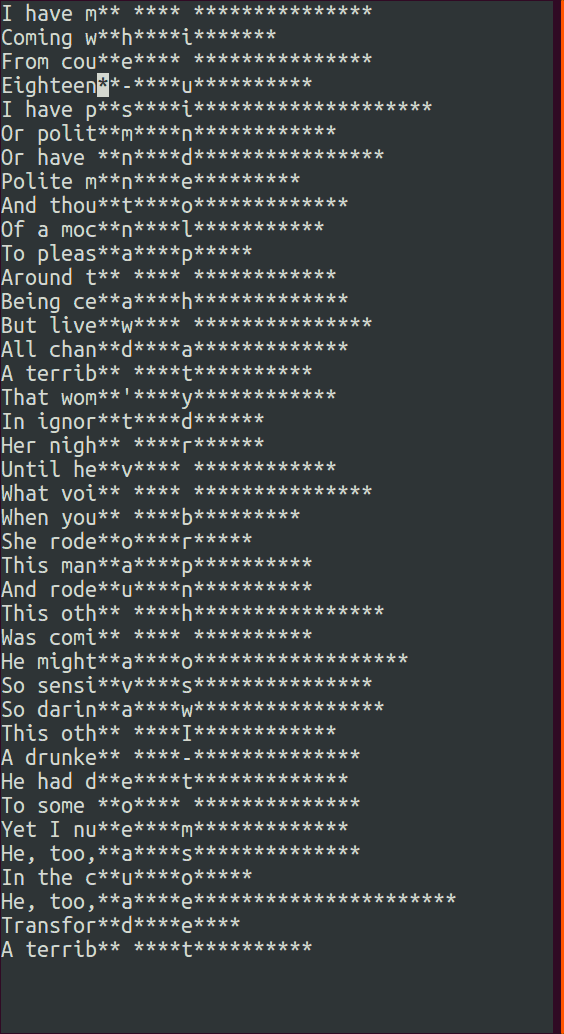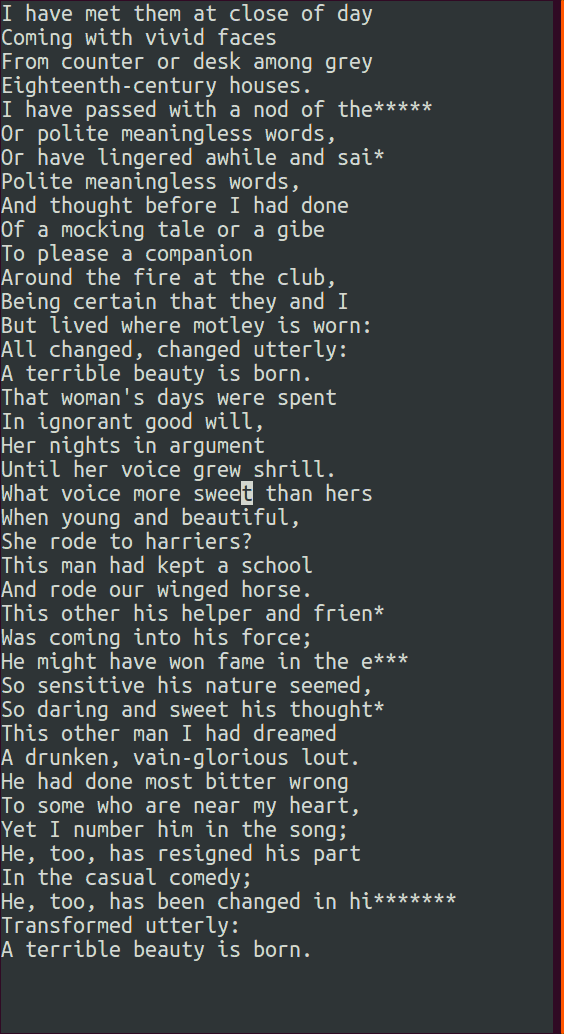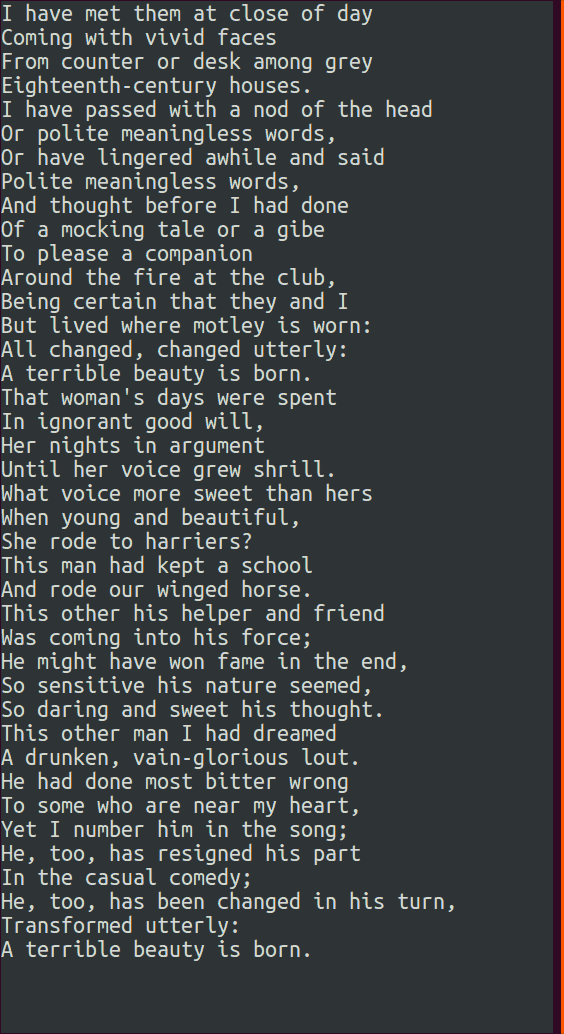
The source code for Challenge 19 along with the rest are available on github. The repo has been dormant lately due to a lack of free time, but I do intend to tackle Set 5 soon.